
科技博主Avi Chawla在X上发了一条长帖,详细拆解了月之暗面Kimi团队刚刚发布的一篇技术报告。帖子发出后不久,马斯克回复说:“月之暗面做出了令人印象深刻的结果”。马斯克在AI领域的表态向来以挑剔著称,甚至曾批评过Anthropic和OpenAI。他自己的xAI最近也在经历大规模重组,多位华人联合创始人离职,Grok的表现也不尽如人意。然而,在这个关键时刻,他对一家中国AI公司的技术论文表示认可,确实出人意料。
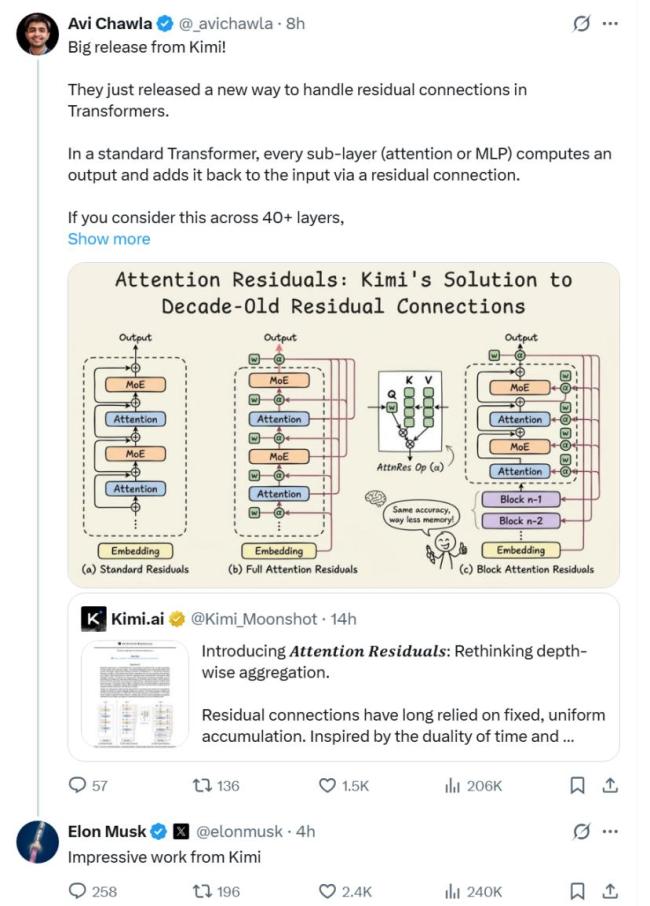
被马斯克点赞的这篇论文实际上是一篇纯粹的技术论文,它提出了一种新的方式,试图替换掉Transformer架构里一个自2015年以来几乎没人动过的基础组件。尽管普通用户可能不会直接感受到这篇论文的影响,但它触及了整个深度学习的基石。
要理解这篇论文的内容,需要了解现代大语言模型,无论是GPT、Claude还是国内的一些模型,其底层架构都是Transformer。Transformer之所以能训练到几十层甚至上百层而不崩溃,是因为“残差连接”机制在起作用。残差连接的原理是每一层网络在做完计算后,将自己的输出和输入加在一起传到下一层,这样梯度在反向传播时可以直达底层,不会因为层数太深而消失。但这种“加法”是完全平等的,导致早期层的信息逐渐被稀释,后期层的信息变得不稳定,这就是所谓的“PreNorm稀释”。
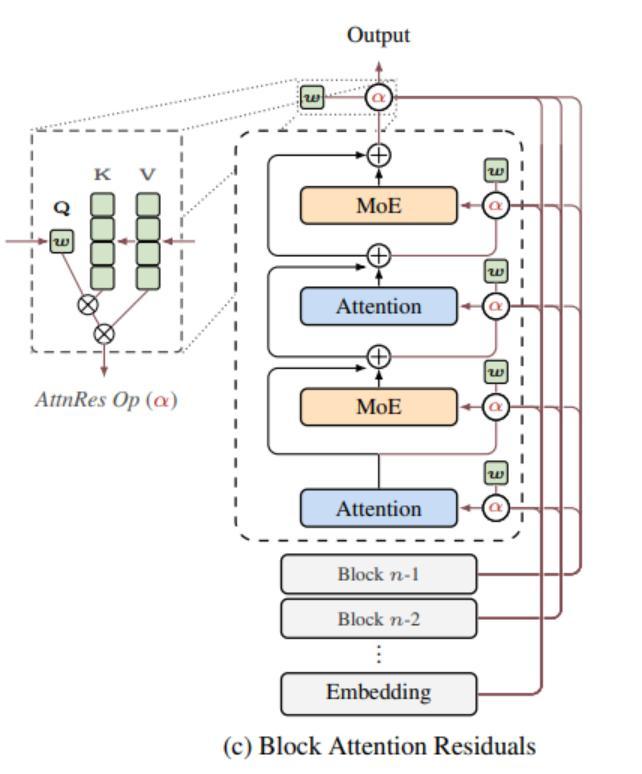
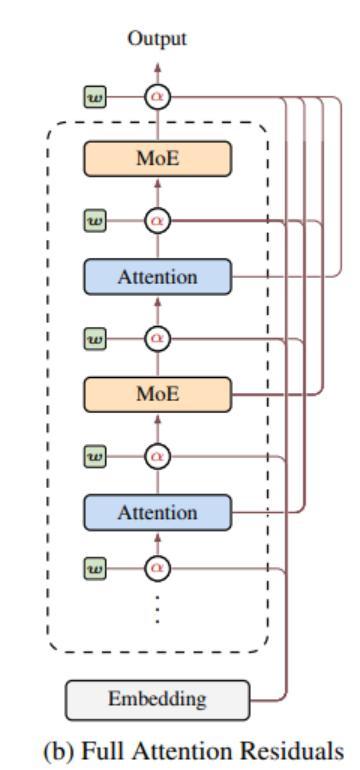
Kimi团队注意到这个问题,并提出了一种新的方法——全注意力残差。具体做法是给每一层赋予一个可学习的查询向量,这个向量会对之前所有层的输出做一次注意力计算,产生一组归一化的权重。当前层的输入不再是之前所有层输出的简单求和,而是按照这组权重的加权组合。然而,全注意力残差在实际应用中存在内存和通信开销问题,因此他们又提出了块注意力残差,将所有层分成若干个块,每个块内部使用传统的残差连接,块与块之间使用注意力机制选择性聚合。这样只需要存储和传输每个块的汇总表示,大大降低了内存占用。
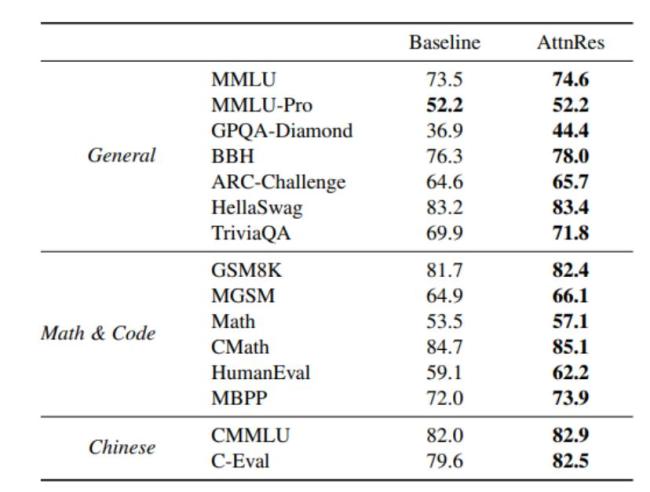
Kimi团队还进行了一系列实验,验证了这一改进在不同模型规模下的有效性。结果显示,注意力在所有计算预算下都优于基线,效果相当于用1.25倍的计算量训练出的基线模型。此外,他们在自己的大模型上进行了实战验证,结果表明块注意力残差确实缓解了PreNorm稀释问题,各层输出的幅度保持在一个相对稳定的范围内,梯度分布也更加均匀。
月之暗面正处于上市的关键时期,近期完成了多轮融资,估值迅速增长。然而,融资顺利并不意味着没有争议。OpenClaw创始人彼得·斯坦伯格公开质疑月之暗面的Kimi Claw产品,认为其云端部署模式违背了OpenClaw的设计理念,存在安全和隐私风险。斯坦伯格的质疑在社区中产生了影响,一些用户表示暂时不会使用该产品。
尽管如此,马斯克的那条回复为月之暗面带来了正面影响。虽然这两件事看似无关,但在舆论场上,它们会被放在一起解读。马斯克的认可对正在进行新一轮融资的月之暗面来说时机极佳,引发了更多人关注这篇论文。一个十一年没人碰过的组件被重新打开免息配资,接下来会发生什么,谁也不知道。
汇盈配资提示:文章来自网络,不代表本站观点。
相关文章



热点资讯




